Хотел бы с Вами поделиться одним очень интересным тестом производительности кластера RabbitMQ, который недавно провели инженеры Meltwater…
В Meltwater мы используем RabbitMQ для обмена сообщениями. Хотя у нас уже есть несколько кластеров, но недавно возникла потребность в еще одном. Это заставило нас задать себе вопрос: а как влияет аппаратная конфигурация сервера, выбранного для кластера, на скорость передачи сообщений? Должны ли мы увеличить количество ядер процессора? Или, может быть, выбрать более быстрые диски? На что еще мы должны обратить внимание, чтобы получить максимальную производительность от RabbitMQ? Эта статья пытается ответить на эти вопросы.
TL;DR Увеличение количества ядер процессора и увеличение скорости диска оказывают незначительное влияние на скорость передачи сообщений через RabbitMQ кластер с высокодоступными постоянными очередями. Для получения наилучших результатов все очереди должны находиться на одном и том же узле кластера и все клиенты должны подключаться только к этому же узлу.
Тестовая конфигурация
Для создания тестовой среды, нами было создано несколько инстансов AWS EC2 разных типов. Производительность сети между узлами кластера была измерена с помощью утилиты Iperf.
| Тип инстанса | Ядра процессора | Потоки Hyper-threading | Частота процессора | Память, Гб | Скорость сети, Гбит/с |
|---|---|---|---|---|---|
| r3.xlarge | 2 | 4 | 2500 | 30.5 | 1.0 |
| r3.2xlarge | 4 | 8 | 2500 | 64 | 1.1 |
| r3.4xlarge | 8 | 16 | 2500 | 128 | 2.2 |
| c3.2xlarge | 4 | 8 | 2900 | 15 | 1.1 |
Во всех тестах мы использовали два инстанса одного типа для создания RabbitMQ кластера. Для генерации нагрузки использовался инстанс r3.2xlarge с Java client PerfTest tool. Все инстансы создавались с дисками SSD Instance Store.
На все тестовые очереди были зеркальными (применена политика ha-mode) и все сообщения отправлялись как постоянные (delivery_mode=2). В тестах с одной очередью, использовалось 10 издателей и потребителей для этой очереди. В испытаниях с 10, 20 и 30 очередями, было по одному издателю и потребителю на очередь. Производительность кластера указана в сообщениях в секунду, суммарно для всех очередей. Другие параметры проведения тестов описаны в следующей таблице.
| Параметр | Значение |
|---|---|
| Версия RabbitMQ | 3.6.5 |
| Версия Erlang | 19 |
| Версия CentOS | 7 |
| Длительность тестирования | 60 сек |
| Размер сообщения | 4000 Байт |
Добавление процессорных ядер
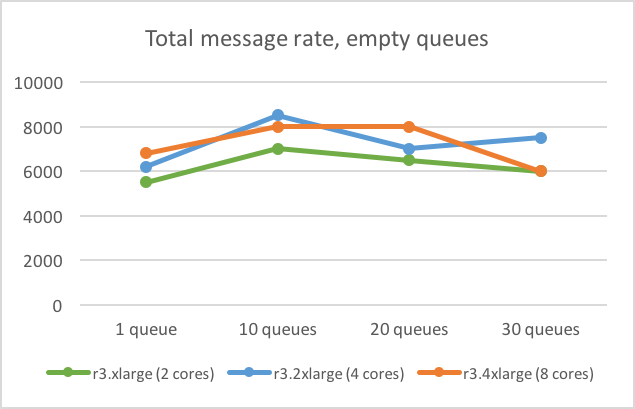
Чтобы определить, как увеличение количества ядер процессора влияет на производительность, мы протестировали три различных типа инстансов с 2, 4 и 8 ядрами (r3.xlarge, r3.2xlarge и r3.4xlarge).
Повышение производительности, при удвоении числа ядер, оказалось весьма скромным. При увеличении с 2 до 4 ядер, скорость передачи сообщений увеличилась всего на 13% (с 5500 до 6200) в тесте с одной очередью. Повторное удвоение количества ядер, с 4 до 8, увеличило скорость только на 10% (с 6200 до 6800). Аналогичные результаты были получены и в тестах с 10, 20 и 30 очередями. В некоторых случаях производительность с большим количеством ядер даже была хуже, что можно увидеть на графике ниже.
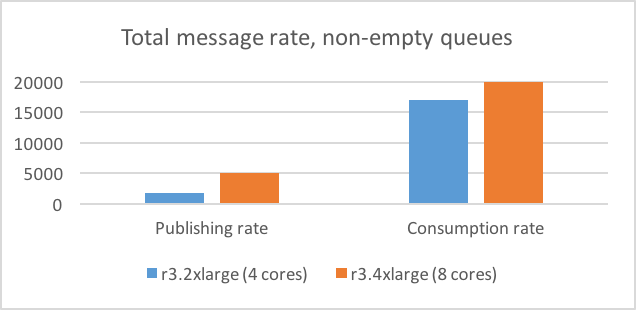
Чтоб определить, как RabbitMQ будет вести себя в ситуации, когда потребители не успевают обрабатывать поступающие сообщения, мы также провели тест с 10 очередями, в каждой из которых к началу теста уже было по 500000 сообщений. В таком варианте, при удвоении числа ядер (с 4 до 8), скорость публикации сообщений более чем удвоились (с 1750 до 5000), а скорость потребления увеличилось примерно на 10% (с 17000 до 20000). Другими словами, похоже что число процессорных ядер оказывает больше влияния на производительность больших очередей, чем пустых.
Увеличение тактовой частоты процессора
Другой вопрос, который у нас был — как частота процессора будет влиять на скорость передачи сообщений. Чтоб понять это мы сравнили инстансы r3 с 2500 МГц процессорами и c3 инстансы с 2900 МГц процессорами. Результаты испытаний для инстансов c3.2xlarge с 4 быстрыми ядрами были аналогичны результатам показаным инстансами r3.4xlarge с 8 более медленными ядрами процессора, т.е. частота процессора не оказывает большого влияния на производительность очереди.
Повышение производительности диска
Мы хотели бы знать, будут ли более быстрые диски влиять на производительность RabbitMQ. Для проверки были созданы два кластера на c3.2xlarge инстансах. На одном кластере мы использовали только один из двух твердотельных 80 Гб дисков. На втором, для получения большей скорости операций записи и чтения, был создан RAID 0 с помощью двух твердотельных дисков. При этом, скорость записи на диск второго кластера увеличилась на 60%, с 800 Мб/с до 1.3 Гб/с.
B в этом случае, повышение эффективности работы кластера RabbitMQ было небольшим. Для одной очередью скорость передачи сообщений увеличилась на 5% (с 6600 до 6900). При 10 очередях, увеличение также составило 5% (с 9000 до 9500).
Повышение производительности сети
Чтобы проверить, как скорость сообщения зависит от сетевой производительности, мы провели тест на сетях с различными задержками и пропускной способностью. Задержка в одной AWS Availability Zone меньше, чем между такими зонами. Замеры скорости сообщений для кластеров с узлами в одной и той же зоне и в разных зонах не показали существенных различий в наших тестах. Для того, чтобы убедиться, что пропускная способность сети между узлами кластера не является узким местом, мы использовали инстансы с различной пропускной способностью сети. В наших тестах, r3.4xlarge имел в два раза больше пропускной способности по сравнению с r3.2xlarge, но скорость передачи сообщений на них была почти одинакова, как это можно увидеть на самом первом графике.
К какому узлу кластера RabbitMQ подключаться?
Как уже было отмечено, скорость передачи сообщения намного лучше, если и издатели, и потребители подключаются к узлу кластера, на котором и находится очередь (мастер-узел). В наших тестах скорость передачи сообщений упала более чем в два раза (с 6200 до 3000) в тесте с одной очередью, а для 10 очередей снизилось на 40% (с 8000 до 5000). Производительность RabbitMQ хуже в любой конфигурации, где потребители или издатели подключаются к узлу с зеркалом очереди.
Распределение нагрузки по нескольким узлам
Наконец, хотелось бы понять, как производительность будет увеличиваться, если нагрузку распределить на два узла путем равномерного разделения очередей на разные узлы. Производители и потребители затем подключаются к соответствующим мастер-узлам. В тесте с 30 очередями скорость передачи уменьшилась на 20% (с 7500 до 6000).
Резюме
Если у вас есть RabbitMQ кластер с высокодоступными очередями и постоянными сообщениями, то верно следующее:
• Удвоение количества ядер процессора оказывает большее влияние на пропускную способность для больших очередей.
• Повышение скорости дисковой системы, путем создания RAID 0, повышает скорость передачи сообщений незначительно.
• При подключении не к мастер-узлу, производительность кластера падает значительно, в худшем случае, в два раза.
• Распределение нагрузки, путем распределения очередей по узлам кластера, снижает производительность.